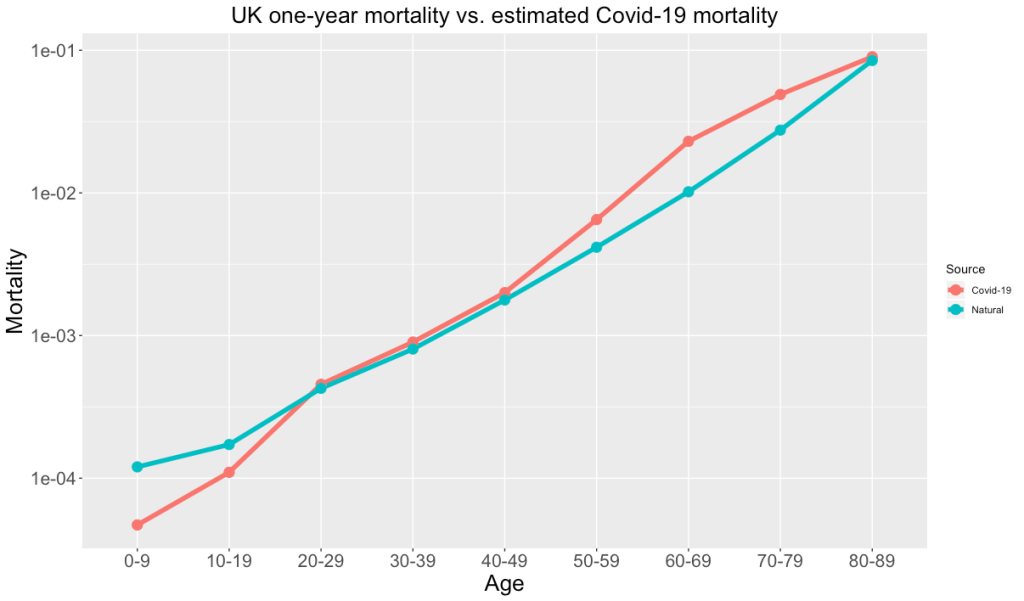
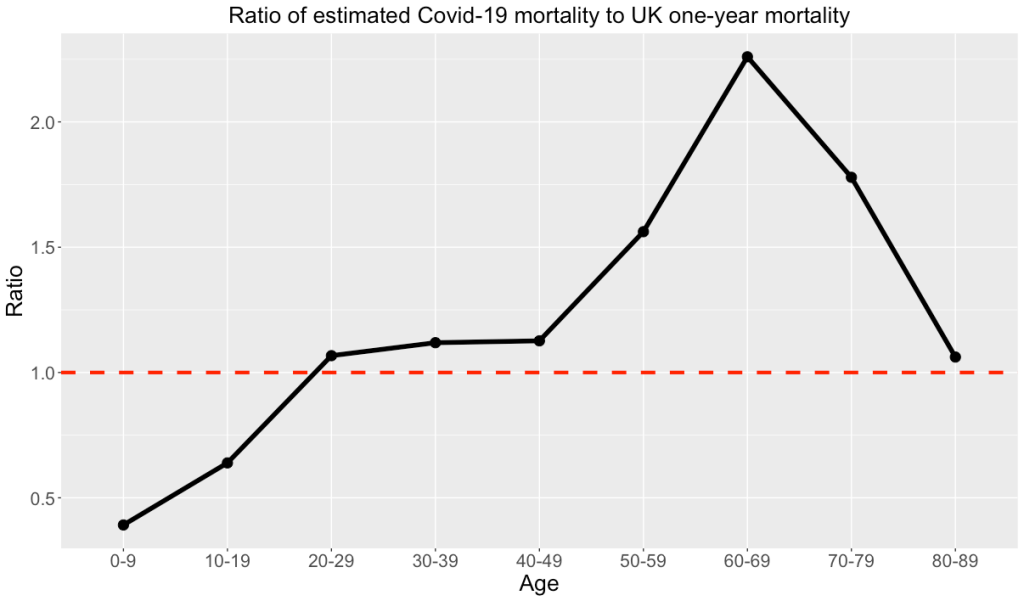
I’ve always heard of the Metropolis algorithm having been invented for H-bomb calculations by Nicholas Metropolis and Edward Teller. But I was just looking at the original paper, and discovered that there are five authors: Metropolis, Rosenbluth, Rosenbluth, Teller, and Teller. Particularly striking having two repeated surnames, and a bit of research uncovers that these were two married couples: Arianna Rosenbluth and Marshall Rosenbluth, and Augusta Teller and Edward Teller. In particular, Arianna Rosenbluth (née Wright) appears to have been a formidable character, according to her Wikipedia page: She completed her physics PhD at Harvard at the age of 22.
In keeping with the 1950s conception of computer programming as women’s work, the two women were responsible, in particular, for all the programming — a heroic undertaking in those pre-programming language days, on the MANIAC I — and Rosenbluth in particular did all the programming for the final paper.
And also in keeping with the expectations of the time, and more depressingly, according to the Wikipedia article “After the birth of her first child, Arianna left research to focus on raising her family.”