The Guardian is reporting on the inquest results concerning the death by suicide of a physics student at Exeter University in 2021. Some details sound deeply disturbing, particularly the account of his family contacting the university “wellbeing team” to tell them about his problematic mental state, after poor exam results a few months earlier (about which he had also written to his personal tutor), but
that a welfare consultant pressed the “wrong” button on the computer system and accidentally closed the case. “I’d never phoned up before,” said Alice Armstrong Evans. “I thought they would take more notice. It never crossed my mind someone would lose the information.” She rang back about a week later but again the case was apparently accidentally closed.
Clearly this university has structural problems with the way it cares for student mental health. I’m inclined, though, to focus on the statistics, and the way they are used in the reporting to point at broader story. At Exeter, we are told, there have been (according to the deceased student’s mother) 11 suicides in the past 6 years. The university responds that “not all of the 11 deaths have been confirmed as suicides by a coroner,” and the head of physics and astronomy said “staff had tried to help Armstrong Evans and that he did not believe more suicides happened at Exeter than at other universities.”
This all sounds very defensive. But the article just leaves these statements there as duelling opinions, whereas some of the university’s claims are assertions of fact, which the journalists could have checked objectively. In particular, what about the claim that no more suicides happen at Exeter than at other universities?
While suicide rates for specific universities are not easily accessible, we do have national suicide rates broken down by age and gender (separately). Nationally, we see from ONS statistics that suicide rates have been roughly constant over the past 20 years, and that there were 11 suicides per 100,000 population in Britain in 2021. That is, 16/100,000 among men and 5.5/100,000 among women. In the relevant 20-24 age group the rate was also 11. Averaged over the previous 6 years the suicide rate in this age group was 9.9/100,000; if the gender ratio was the same, then we get 14.4/100,000 men and 5.0/100,000 women.
According to the Higher Education Statistics Agency, the total number of person years of students between the 2015/2016 and 2020/2021 academic years were 81,795 female, 69,080 male, and 210 other. This yields a prediction of around 14.5 deaths by suicide in a comparable age group over a comparable time period. Thus, if the number 11 in six years is correct, it is still fewer deaths by suicide at the University of Exeter than in comparable random sample of the rest of the population.
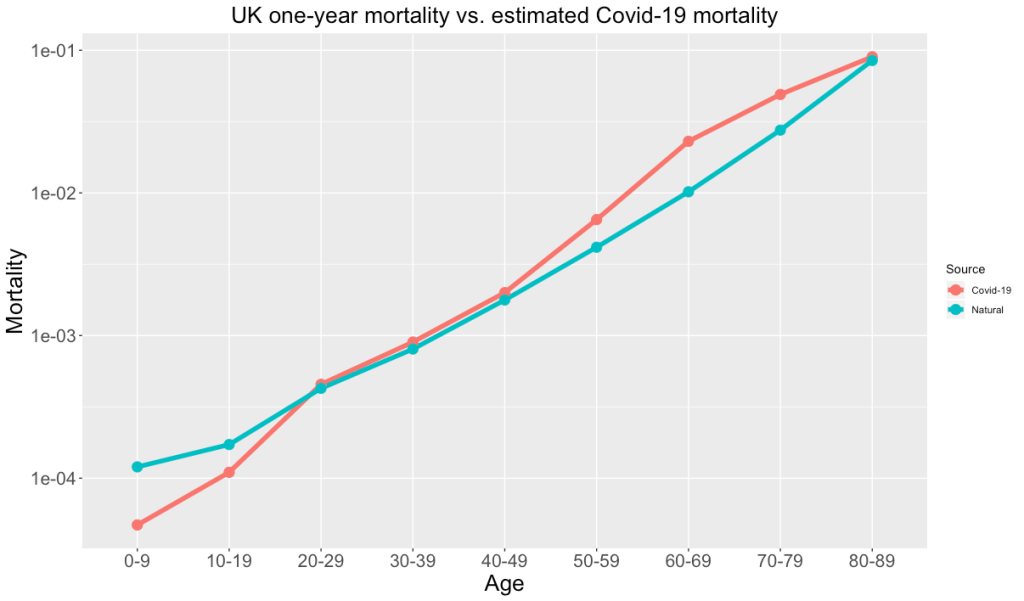
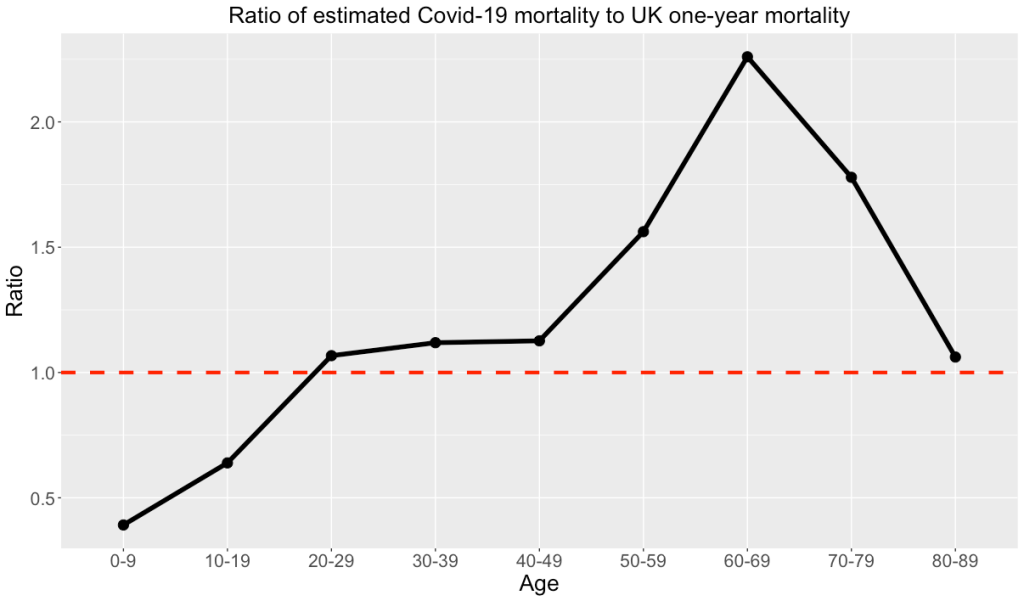
It’s not that this young man’s family should be content that this is just one of those things that happens. There was a system in place that should have protected him, and it failed. Students are under a lot of stress, and need support. But non-students are also under a lot of stress, and also need support. It’s not that the students are being pampered. They definitely should have institutionalised well-trained and sympathetic personnel they can turn to in a crisis. Where where are the “personal tutors” for the 20-year-olds who aren’t studying, but who are struggling with their jobs, or their families, or just the daily grind of living? And what about the people in their 40s and 50s, whose suicide rates are 50% higher than those of younger people?
Again, it would be a standard conservative response to say, We don’t get that support, so no one should get it. Suck it up! A more compassionate response is to say, students obviously benefit from this support, so let’s make sure it’s delivered as effectively as possible. And then let’s think about how to ensure that everyone who needs it gets helped through their crises.