
Last week I suggested that it could very well be that a second Brexit referendum would stumble into Arrow’s paradox, with Remain preferred to soft Brexit, soft Brexit preferred to no deal, and No Deal preferred to Remain. I wasn’t expecting rapid confirmation, but here it is, from a poll of about 1000 British adults:
Tag: polls
The Silver Standard, Part 3: The Reckoning
One of the accusations most commonly levelled against Nate Silver and his enterprise is that probabilistic predictions are unfalsifiable. “He never said the Democrats would win the House. He only said there was an 85% chance. So if they don’t win, he has an out.” This is true only if we focus on the top-level prediction, and ignore all the smaller predictions that went into it. (Except in the trivial sense that you can’t say it’s impossible that a fair coin just happened to come up heads 20 times in a row.)
So, since Silver can be tested, I thought I should see how 538’s predictions stood up in the 2018 US House election. I took their predictions of the probability of victory for a Democratic candidate in all 435 congressional districts (I used their “Deluxe” prediction) from the morning of 6 November. (I should perhaps note here that one third of the districts had estimates of 0 (31 districts) or 1 (113 districts), so a victory for the wrong candidate in any one of these districts would have been a black mark for the model.) I ordered the districts by the predicted probability, to compute the cumulative predicted number of seats, starting from the smallest. I plot them against the cumulative actual number of seats won, taking the current leader for the winner in the 11 districts where there is no definite decision yet.
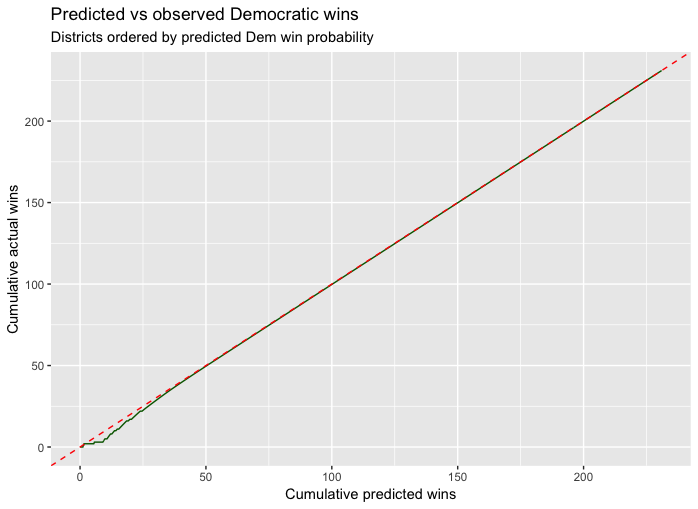
The predicted number of seats won by Democrats was 231.4, impressively close to the actual 231 won. But that’s not the standard we are judging them by, and in this plot (and the ones to follow) I have normalised the predicted and observed totals to be the same. I’m looking at the cumulative fractions of a seat contributed by each district. If the predicted probabilities are accurate, we would expect the plot (in green) to lie very close to the line with slope 1 (dashed red). It certainly does look close, but the scale doesn’t make it easy to see the differences. So here is the plot of the prediction error, the difference between the red dashed line and the green curve, against the cumulative prediction:

There certainly seems to have been some overestimation of Democratic chances at the low end, leading to a maximum cumulative overprediction of about 6 (which comes at district 155, that is, the 155th most Republican district). It’s not obvious whether these differences are worse than you would expect. So in the next plot we make two comparisons. The red curve replaces the true outcomes with simulated outcomes, where we assume the 538 probabilities are exactly right. This is the best case scenario. (We only plot it out to 100 cumulative seats, because the action is all at the low end. The last 150 districts have essentially no randomness. The red curve and the green curve look very similar (except for the direction; the direction of the error is random). The most extreme error in the simulated election result is a bit more than 5.
What would the curve look like if Silver had cheated, by trying to make his predictions all look less certain, to give himself an out when they go wrong? We imagine an alternative psephologist, call him Nate Tarnished, who has access to the exact true probabilities for Democrats to win each district, but who hedges his bets by reporting a probability closer to 1/2. (As an example, we take the cumulative beta(1/2,1/2) distribution function. this leaves 0, 1/2, and 1 unchanged, but .001 would get pushed up to .02, .05 is pushed up to .14, and .2 becomes .3. Similarly, .999 becomes .98 and .8 drops to .7. Not huge changes, but enough to create more wiggle room after the fact.
In this case, we would expect to accumulate much more excess cumulative predicted probability on the left side. And this is exactly what we illustrate with the blue curve, where the error repeatedly rises nearly to 10, before slowly declining to 0.

I’d say the performance of the 538 models in this election was impressive. A better test would be to look at the predicted vote shares in all 435 districts. This would require that I manually enter all of the results, since they don’t seem to be available to download. Perhaps I’ll do that some day.
The Silver Standard: Stochastics pedagogy
I have written a number of times in support of Nate Silver and his 538 project: Here in general, and here in advance of the 2016 presidential elections. Here I want to make a comment about his salutary contribution to the public understanding of probability.
His first important contribution was to force determinism-minded journalists (and, one hopes, some of their readers) to grapple with the very notion of what a probabilistic prediction means. In the vernacular, “random” seems to mean only a fair coin flip. His background in sports analysis was helpful in this, because a lot of people spend a lot of time thinking about sports, and they are comfortable thinking about the outcomes of sporting contests as random, where the race is not always to the swift nor the battle to the strong, but that’s the way to bet. People understand intuitively that the “best team” will not win every match, and winning 3/4 of a large number of contests is evidence of overwhelming superiority. Analogies from sports and gaming have helped to support intuition, and have definitely improved the quality of discussion over the past decade, at least in the corners of the internet where I hang out.*
Frequently Silver is cited directly for obvious insights like that an 85% chance of winning (like his website’s current predicted probability of the Democrat’s winning the House of Representatives) is like the chance of rolling 1 through 5 on a six-sided die, which is to say, not something you should take for granted. But he has also made a great effort to convey more subtle insights into the nature of probabilistic prediction. I particularly appreciated this article by Silver, from a few weeks ago.
As you see reports about Republicans or Democrats giving up on campaigning in certain races for the House, you should ask yourself whether they’re about to replicate Clinton’s mistake. The chance the decisive race in the House will come somewhere you’re not expecting is higher than you might think…
It greatly helps Democrats that they also have a long tail of 19 “lean R” seats and 48 “likely R” seats where they also have opportunities to make gains. (Conversely, there aren’t that many “lean D” or “likely D” seats that Democrats need to defend.) These races are long shots individually for Democrats — a “likely R” designation means that the Democratic candidate has only between a 5 percent and 25 percent chance of winning in that district, for instance. But they’re not so unlikely collectively: In fact, it’s all but inevitable that a few of those lottery tickets will come through. On an average election night, according to our simulations, Democrats will win about six of the 19 “lean R” seats, about seven of the 48 “likely R” seats — and, for good measure, about one of the 135 “solid R” seats. (That is, it’s likely that there will be at least one total and complete surprise on election night — a race that was on nobody’s radar, including ours.)
This is a more subtle version of the problem that all probabilities get rounded to 0, 1, or 1/2. Conventional political prognosticators evaluate districts as “safe” or “likely” or “toss-up”. The likely or safe districts get written off as certain — which is reasonable from the point of view of individual decision-making — but cumulatively a large number of districts with a 10% chance of being won by the Democrat are simply different from districts with a 0% chance. It’s a good bet that the Republican will win each one, but if you have 50 of them it’s a near certainty that the Democrats will win at least 1, and a strong likelihood they will win 8 or more.
The analogy to lottery tickets isn’t perfect, though. The probabilities here don’t represent randomness so much as uncertainty. After 5 of these “safe” districts go the wrong way, you’re almost certainly going to be able to go back and investigate, and discover that there was a reason why it was misclassified. If you’d known the truth, you wouldn’t have called it safe it all. This enhances the illusion that no one loses a safe seat — only, toss-ups can be mis-identified as safe.
* On the other hand, Dinesh D’Souza has proved himself the very model of a modern right-wing intellectual with this tweet:
Written wordplay
Isaac Asimov, in a side-remark in his Treasury of Humor, mentioned a conversation in which a participant expressed outrage at a politician blathering about “American goals”. “His specialty is jails, not goals,” and then seeming to expect some laughter. It was only on reflection that Asimov realised that the speaker, who was British, had spelled it gaols in his mind.
I was reminded of this by this Guardian headline:
Labour has shifted focus from bingo to quinoa, say swing voters
The words bingo and quinoa look vaguely similar on the page, but they’re not pronounced anything alike. Unlike Asimov’s example, this wordplay is in writing, so spelling is important. My feeling is that wordplay has to be fundamentally sound-based, so this just doesn’t work for me. Maybe the Guardian editors believe in visual wordplay.
Alternatively, maybe they don’t know how quinoa is pronounced.
Good words
There has been a lot of reporting on this recent poll, where people were asked what word first came to mind when they thought of President Trump. Here are the top 20 responses (from 1,079 American adults surveyed):
idiot 39 incompetent 31 liar 30 leader 25 unqualified 25 president 22 strong 21 businessman 18 ignorant 16 egotistical 15 asshole 13 stupid 13 arrogant 12 trying 12 bully 11 business 11 narcissist 11 successful 11 disgusting 10 great 10
The fact that idiot, incompetent, and liar head the list isn’t great for him. But Kevin Drum helpfully coded the words into “good” and “bad”:
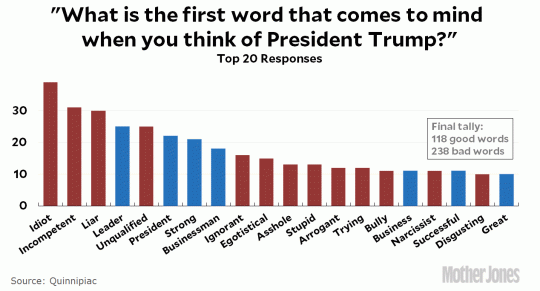
What strikes me is that even the “good” words aren’t really very good. If you’re asked what word first comes to mind when you think of President Trump and you answer president, that sounds to me more passive-aggressive than positive. Similarly, you need a particular ideological bent to consider businessman and business to be inherently positive qualities. Leader — I don’t know, I guess der Führer is a positive figure for those who admire that sort of thing. Myself, I prefer to know where we’re being led. If we include that one, there are 4 positive words, 4 neutral words, and 12 negative. (I’m including trying as neutral because I don’t know if people mean “working hard to do his job well”, which sounds like at least a back-handed compliment, or “trying my patience”.)
Why were the polls so wrong?
While Tuesdays election result is a global disaster, it is most immediately distressing for three groups: American Latinos, American Muslims, and American pollsters.
First of all, let us dispel with the idea (that I have heard some propound) that they weren’t wrong. Huge numbers of polls done independently in multiple states gave results that were consistently at variance in the same direction with the actual election results. I can see three kinds of explanations:
- The pollsters shared a mistaken idea or methodology for correcting their tiny unrepresentative samples for differential turnout.
- Subjects lied about their voting intentions.
- Subjects changed their minds between the last poll and the election.
3 seems unlikely to account for a lot, as it seems implausible to suppose that many people changed their minds so rapidly. 2 is plausible, but hard to check and difficult impossible to correct. 1 is a nice technical-sounding explanation, and certainly seems like there must be some truth to it. Except, probably not much. As evidence, I bring the failure of VoteCastr.
Slate magazine teamed up with the big-data firm VoteCastr to trial a system of estimating votes in real time. Ahead of time they did extensive polling to fit an extensive model to predict an individual’s vote (probabilistically) as a function of several publicly-available demographic variables. Then they track records of who actually voted, and update their totals for the number of votes for each candidate accordingly.
Sounds like a perfectly plausible scheme. And it bombed. For instance, their final projection for Florida was 4.9 million (actually, 4,225,249) for Clinton and 4.6 million for Trump, a lead of about 3% for Clinton. The real numbers were 4.5 million and 4.6 million, a lead of 1.3% for Trump. (The difference in the total seems to be mainly due to votes for other candidates, though the total number of Florida votes in VoteCastr is about 100,000 more than in the official tally, which I find suspicious.) They projected a big victory for Clinton in Wisconsin.
The thing is, this removes the uncertainty related to reason 1: They know exactly who came to vote, and they’re matched by age, sex, and party registration. Conclusion: Estimating turnout is not the main problem that undermined this year’s presidential election polls.
Waiting for Armageddon
The US presidential election is now just 4 days away. It seems to me that people are not taking the danger seriously. In particular, last week, in the hour after the FBI started its intervention to bring on the apocalypse (more work for them, I suppose), it was reported that the S&P500 stock index fell by about 1%. If we suppose that the FBI’s announcement made a Trump victory 2% more likely, that suggests an expectation that Trump would wipe 50% off the value of the stock market. Yet that doesn’t seem to be incorporated into the current value of the markets. It’s almost as though investors are in denial: When forced to focus on the Trump danger they rate it apocalyptic, but as soon as the news quiets down — within minutes — they go back to treating the probability as 0.
I’d like to believe Sam Wang’s projections, that the election result is all but certain for Clinton. Nothing is all but certain, least of all the future. Nate Silver’s reasoning, leading to about a 2/3 chance for Clinton, seems to me very sound: Trump will win only if he wins about half a dozen states where he has about a 50% chance. That sounds like about a 2% chance, except that they are unlikely to be independent. The reality is likely to be somewhere between 2% and 50%. Where it is, is almost impossible to judge. I’m slightly more hopeful than that because I believe in the power of Clinton’s organisation. But how much more?
But even 2%, for the risk of a crybaby fascist as president, is far too much. It’s not clear to me how the US can come back from this disaster, even if Trump loses.
Pollster infallibility
I was reading this article by John Cassidy of the New Yorker about the current state of the US presidential election campaign, according to the polls, and was surprised by this sentence:
Of course, polls aren’t infallible—we relearned that lesson in the recent Brexit referendum.
It hardly requires any major evidence to argue against the straw man that the polls are infallible, but I didn’t recall any notable poll failure related to Brexit; on the contrary, I was following this pretty closely, and it seemed that political commentators were desperately trying to discount the polls in the weeks leading up to the referendum, arguing that the public would ultimately break for the status quo, no matter what they were telling the pollsters. I looked it up on Wikipedia:

So it looks like the consensus of the polls was that Leave and Remain were about equal, with a short-term trend toward leave, and about 10% still undecided. Hardly a major case against the polls being infallible when Leave won by a few percent…
