
Disquisition on medical statistics in The Guardian
A recent front-page article in The Guardian claimed to show that small NHS hospitals are killing people. “Huge disparity in NHS death rates revealed” was one headline. “Patients less likely to die in bigger hospitals“. “Safety in numbers for hospital patients” is another headline. The article makes no secret of its political agenda: “The results strongly suggest that smaller units should close. This presents a major challenge to the health secretary, Andrew Lansley, who has stopped all hospital reorganisation.” Online, Polly Toynbee decries “Hospital populism”, saying “Local hospitals may be loved, but they can kill.” Wow. That’s pretty bad. Here’s the schematic of the story: Smart and selfless experts want to save lives. Dumb public clings to habit (in the form of community hospitals). Evil politicians pander to dumb public, clings to campaign promises. “The health secretary, Andrew Lansley, has now put the project on hold, in line with his election promise to halt hospital closures, to the dismay of experts who believe that lives will continue to be lost.”
Why does Andrew Lansley want to kill people?
Well, how many people does he want to kill, exactly? They analysed number of deaths against number of procedures performed in the hospital for planned abdominal aortic aneurysm (AAA) surgery. Fortunately, the Guardian has published all its data. This is generous and brave, and a great example of openness, after they devoted a huge effort to winkling the data out of hospitals. Despite the Freedom of Information law, hospitals have not been as forthcoming as they are required to be. It is also brave, because publishing the data opens them up to criticisms like this one. They have even gone so far as to publish my letter to the editor. For all this, they ought to be commended.
The data, though, don’t look like what you would expect from these headlines. It’s hard to know if it’s the fault of Peter Holt, the lecturer in vascular surgery to whom the data analysis is attributed; or to the journalists Susan Boseley, Gozde Zorlu, and Rob Evans, who translated the analysis into overheated prose. The data analysis as presented is simply an assemblage of plots (very amateurish-looking, but you can’t really hold that against him, particularly since they probably weren’t intended to be made public) The recent paper by Holt and others is far more modest in its conclusions, despite seeming to have a much clearer statistical story to tell. It meta-analyses several other papers, to show that there is a link between surgeons performing individually a small number of AAA operations annually, and increased mortality. That article, perhaps because it appeared in a scientific journal rather than a newspaper, did not promote a particular political solution. In particular, it made clear that one basic source of confounding is the simple fact that we don’t know if surgeons who perform more operations become better, or if surgeons who are better attract more patients. Despite Polly Toynbee’s sneering over the “have-a-go general surgeon”, Holt’s paper makes clear that the available evidence does not confirm the notion that individual surgeons become better with increasing practice of the same operation.
My guess is, after having spent 18 months fighting for the data, they weren’t keen to come up with a page 12 report saying that smaller hospitals may or may not have a slightly elevated mortality risk for certain procedures. 18 months of Freedom of Information battles make a person ornery. Particularly when you have prior reason to believe that a certain answer will come out, there’s a strong confirmation bias. Particularly when you feel moralistically certain that there is a matter of high principle involved in bringing this result to the public. But statistics is all about uncertainty, and a statistical analysis fails if you don’t make the uncertainty as clear as the top-line answer.
More about the politics is in my letter to the Guardian here. Fundamentally, I think it’s dangerous to be trying to stampede public policy in a particular direction by exaggerating the interpretation of the available data. It’s an intellectual usurpation: Policy makers have to weigh your evidence and your concerns against other evidence and concerns, and you can’t go feeding lead pellets to your own bird to tip the scales.
What are we talking about?
The data describe death rates in 99 NHS hospital units, performing surgery for abdominal aortic aneurysm (AAA). Most of these surgeries are planned, but still result in several percent mortality. When performed in an emergency rupture, mortality is over 30%. I will mostly discuss the planned operations, since this is what The Guardian described. But the emergency operations are an important part of the picture, since closing hospitals (the Guardian’s preferred solution) would inevitably lead to longer transit times for some emergency patients, presumably raising mortality in these cases. (It’s noteworthy that Holt, when he is quoted.
Analysis: Planned operations
I won’t claim that this is a particularly sophisticated analysis. I’m just applying some basic statistical tools — certainly nothing more sophisticated than Holt used in his paper — to quantify the mortality effect of small hospitals. For purposes of this analysis, I will ignore all sources of bias, and simply stipulate that mortality rates are an inherent property of hospitals, depending on nothing but the number of operations performed. (We have, in any case, no data on anything else, though with some effort one could presumably consider various effects of geography.)
Random variation
Those of us who teach statistics learn how unintuitive the basic consequences of random variation can seem to students, but these kinds of questions can confuse even those who are professionally devoted to answering them. For instance, another letter to the Guardian, from Dr John Coakley, Medical director, Homerton University Hospital NHS foundation trust, argues “From the expense point of view we could argue that centres should carry out 100 cases per year per site. From a clinical-quality perspective one could argue that those with mortality in excess of 5% should stop operating. That would leave roughly 30 sites.” Sounds perfectly reasonable, but that means that the threshold for keeping a hospital open is 5 deaths a year. Suppose all 30 sites have actually attained the NHS target rate of 3.5% mortality. In any given year we would expect about 14% of the sites to have 6 or more deaths, thus exceeding the threshold for being shut down. If we extend the assessment over 3 years we would expect 6.5% of the sites to be shut down, purely because of chance variation. And over 5 years each perfectly average hospital has a 3.1% chance of having more than 25 deaths, and so being shut down. Out of 30 hospitals then, even with a 5-year baseline we would expect that one will be shut down for no good reason.
The Guardian used this random variability as its main source of material. That seems to have been the main source of the “huge disparity” headline.
* “Death rates vary from less than one in 50 in some hospitals to more than one in 10 in others.”
* “The most worrying death rates were at Scarborough hospital in Yorkshire, where 29% of patients scheduled in advance for AAA surgery died in the three-year period from 2006 to 2008. The national average was just over 4%… Results for planned surgery at several other hospitals also gave cause for concern, including Gateshead on 12.9%, Hull on 9%, Pennine Acute Trust on 8.4% and Leeds on 7.1%.”
* Matt Thompson, professor of surgery at St George’s and clinical lead for the London cardiovascular review, is quoted “one out of eight people is dying of an elective procedure. That can’t be right.”
Holt includes a plot like this one on the Guardian website, but it wasn’t mentioned directly in any of the Guardian’s articles:
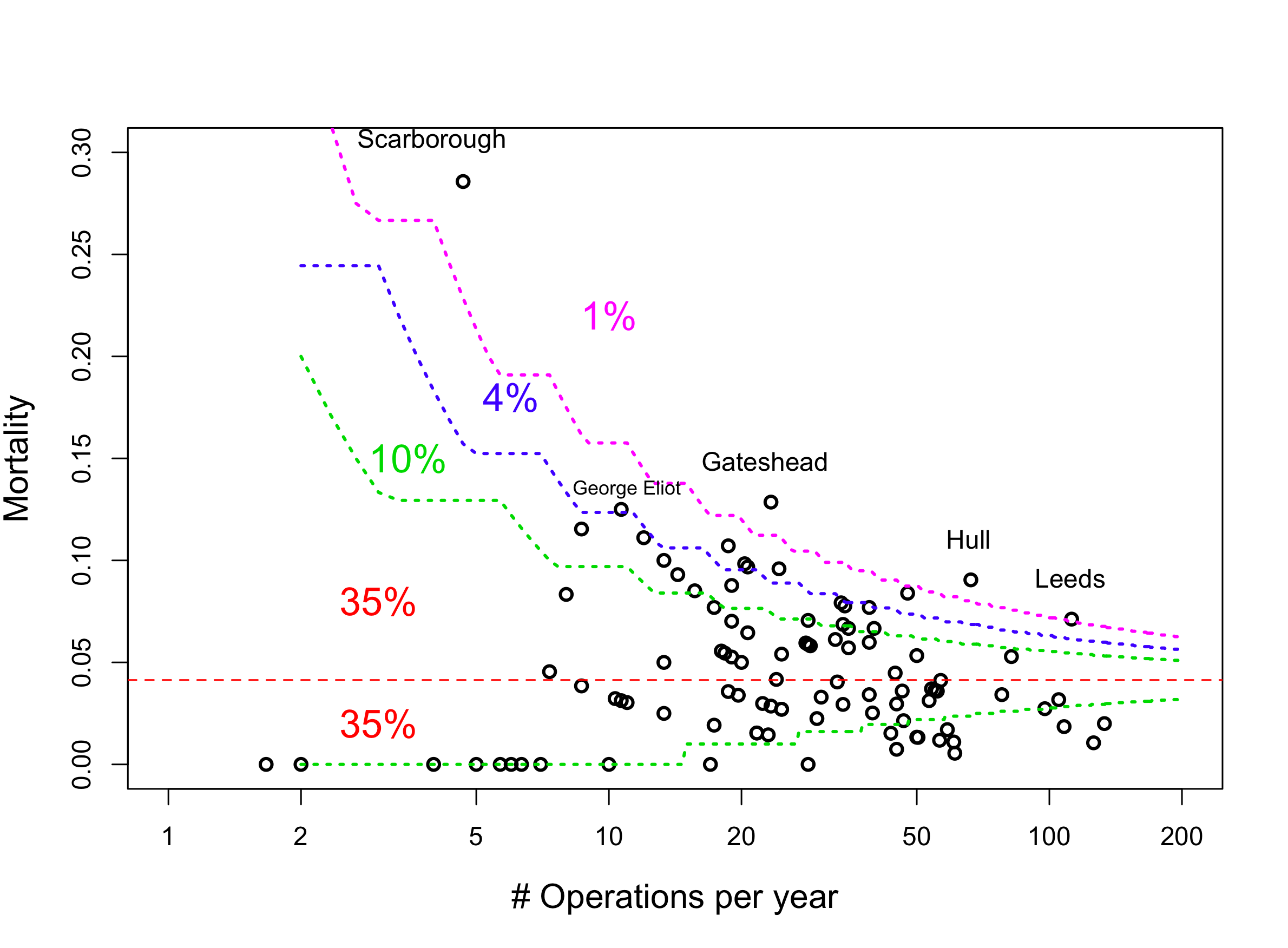
This shows mortality plotted against the number of (planned) AAA operations per year performed over the years 2006-8. (Number of operations has been plotted on a logarithmic scale to spread out the large number of small hospitals.) The red dashed line shows the average mortality over all hospitals. The other dashed lines show show for each number of operations the level of deviation that would be expected with a given probability. They correspond to 70% probability (green), 90% probability (blue), and 98% probability (pink). Thus, we would expect about 70% of the points to lie somewhere between the green curves, 20% between blue and green (10% on each side), 8% between blue and pink, and 2% above the upper pink or below the lower. Since there are 99 hospitals we should expect, purely by chance, if every hospital had exactly the average mortality (4.1%), one unlucky hospital to be above the pink curve, 4 between blue and pink, and 10 between green and blue. In fact, the numbers are 4, 5, and 10.
A couple of points about this: First, the four hospitals in the upper region – the ones with extremely poor performance – are two small hospitals and two large hospitals. Second, the “one out of eight” that Professor Thompson referred to matches 3 hospitals: Gateshead Health, George Eliot Hospital, and Northampton General. Gateshead has 9 deaths in 70 operations, putting it well into the upper region. You would expect that a hospital with the average mortality 4.1% would have 9 deaths in 70 operations only 2 times out of 1000 – prima facie evidence that something is wrong there. (Of course, what is wrong could be simply that they happen to have particularly sick patients.) Northampton General had 3 deaths on 26 operations, putting it well below the blue curve: It’s not even a particularly surprising performance. While 1 patient on average would have died, there was a 9% chance of having 3 deaths. In the middle is George Eliot, with 4 deaths out of 32, instead of the 1 death that would be expected. This is fairly unlikely – only a 4% chance, and standard statistical hypothesis testing would tell us that the mortality rate is “significantly too high”. But there is a problem here of multiple testing. As we have already said, any individual hospital is unlikely to perform so poorly, but we would expect about 4 out of 99 to perform so. Looking at them all together, this “one out of eight” is also not convincing evidence that this hospital has had anything more than a run of bad luck.
Grouping
How can we decide whether there is an overall effect of hospital size on patient mortality? And if there is an effect, how can we estimate its size?
Holt performed the following analysis: The hospitals were ordered by number of operations, and then assembled into five groups, which had approximately equal numbers of operations. The ranges associated with the groups were misidentified, but they are approximately these:
| Range (# operationsin 3 years) |
2-73 |
74-117 |
119-162 |
165-246 |
293-400 |
| Total # operations |
2033 |
1993 |
1969 |
1891 |
2047 |
|
Mortality |
0.057 |
0.052 |
0.034 |
0.035 |
0.029 |
A plot, with bars for 95% confidence intervals is:
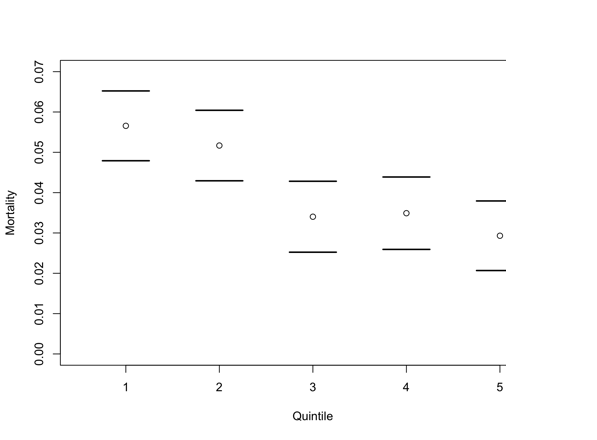
The claim is that there is a “clear threshold effect”, which seems pretty obvious… until you start thinking about how sensitive these results might be to the way we split them up into groups. For instance, if we split them up into six groups instead
| Range (# operationsin 3 years) |
2-67 |
69-102 |
103-139 |
140-169 |
170-246 |
293-400 |
| Total # operations |
1679 |
1683 |
1577 |
1557 |
1390 |
2047 |
|
Mortality |
0.055 |
0.050 |
0.044 |
0.033 |
0.037 |
0.029 |
we see a very different pattern:
 And if we take unequal groups, the monotone pattern could disappear altogether.
And if we take unequal groups, the monotone pattern could disappear altogether.
| Range (# operationsin 3 years) |
2-30 |
31-70 |
72-134 |
135-183 |
199-400 |
| Total # operations |
257 |
1631 |
2642 |
2677 |
2726 |
|
Mortality |
0.043 |
0.058 |
0.050 |
0.028 |
0.036 |

The lowest group has almost exactly average mortality, and the estimates are not clearly trending in any direction.
Which is not to say that there is no trend, or no threshold effect. There does seem to be some sort of downward trend. But it’s not very clear how to be sure with this approach.
Regression: Estimating the effect size
The simplest way – though perhaps not the most accurate – to estimate the overall effect of hospital size on mortality is with some kind of regression. We want to take account in some way of the fact that hospitals with the same size still seem to have substantial variation in their average mortality. This suggests that we use a random effects model. We model log p/(1-p)=q0+A*Size + Hosp, where Size is the total number of operations, p is the mortality probability, and Hosp is the individual hospital effect, assumed to be normally distributed with mean 0 and unknown variance. We fit the data using the glmmPQL function of R. (We get very similar results when we replace Size by log Size.) There are some obvious defects – in particular, the variability among hospitals doesn’t look normal – but nothing that seems to produce any serious errors, and it at least gives us a handle on the overall effect.
The fit is
q0=-2.79 ± 0.12
A =-0.0027 ± 0.00081
(The ± number is the standard error.) So the slope is statistically significantly positive, but need not be very big. An approximate 95% confidence interval for the slope A is (-0.00424,-0.00107). When transformed into mortality probabilities, it becomes something like this:

The black solid line is the line (looks like a curve because of the logarithmic scale) with the central estimate of slope. The green dashed line is the line with the lower bound of slope, while the red dashed line has the upper bound of slope, from the 95% confidence interval. Thus we see that the relative risk corresponding to moving from a 10 operation/year hospital to a 50 operation/year hospital has a 95% confidence interval of about (1.14,1.67). We can now answer the primary question: Assuming, for the sake of argument, that the effect of hospital size is purely about size, so that making hospitals larger will inexorably reduce their mortality by the amount predicted by the regression equation. (This would not be the case if, for example, smaller hospitals simply tend to attract inferior surgeons, who would still be performing worse if some of them were forced to specialise in AAA operations. Or if some hospitals are performing more of these operations because of their superior reputation, so that concentrating the efforts of the inferior hospitals might not change their results.)
There are (at least) two ways we might use the regression, depending on what we think the proposal for increasing hospital size might be. We might ignore estimates of individual hospital quality, and suppose that all hospitals which do fewer than x elective AAA operations a year will be shut (or stop doing these operations); in their place, new centres of size about x will be created, and they will have the same mortality rate as hospitals currently of size x. This produces a picture something like this:

The black dots show the central estimate for mortality gains when we concentrate operations from units of size x per annum into units of size exactly x per annum. The red are the upper edge of the confidence interval for the slope, the green the lower edge. The reason for the crossover is that when we model a large effect of size on mortality, a size 30 unit ends up looking significantly worse than when we model a small size effect; and, in fact, it looks worse than the hospitals of size smaller than 30 actually were, which is why the mortality “gain” is negative.
Alternatively, we might imagine keeping the current large hospitals, and transferring operations from small into large hospitals. For definiteness, we say that each large hospital receives the same number of transfers, whatever number that needs to be to absorb all the overflow. And just for fun, we suppose that these large hospitals retain their identity, including their (estimated) differences in underlying mortality, which we estimated from the random effects model. Then we get a picture that looks like this:
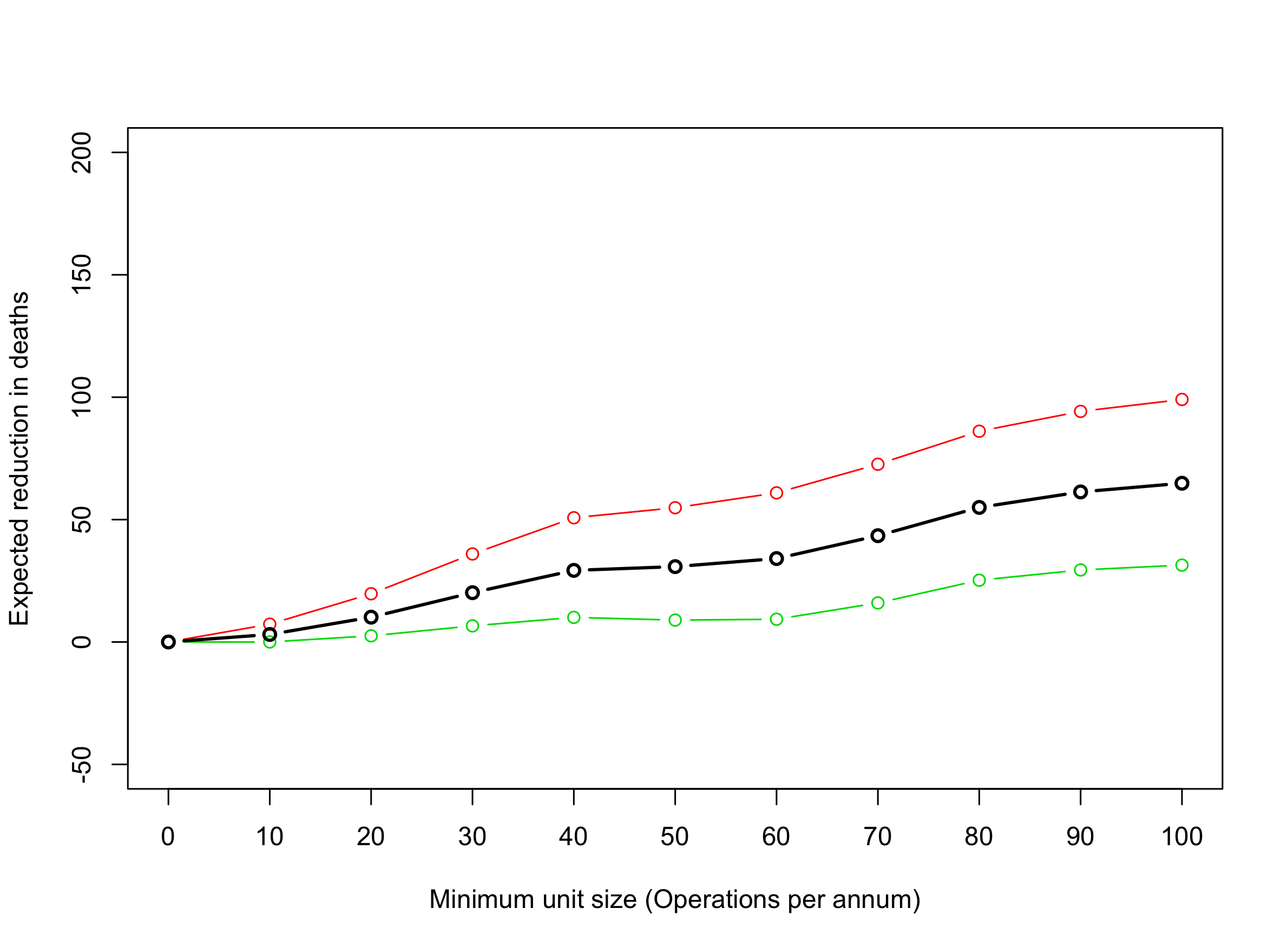
Thus, if we eliminate hospital units smaller than 50/year (as “Some leading surgeons believe [is needed] for best results”) there will (with 95% confidence) be between 9 and 55 fewer deaths (according to model I) or between 26 and 41 fewer (according to model II). Moving up to a minimum of 100/year, model I predicts between 31 and 99 fewer deaths; and model II predicts between 64 and 164 fewer deaths. Is this an emergency? Are the small hospitals killing people? Is this a “huge disparity” in death rates? Well, at least we have specific numbers that each person could judge for him- or herself. (Of course, one could have a go at making a better model, too, but at least this is a plausible start.)
One might say, even if we can save 9 lives, isn’t that worth it? Well, you have to think about the costs – not just money, which seems so tawdry (though perhaps not when you think of the trade-off for other things the NHS might do to save lives with the extra money) – but in disruption of functioning hospitals. The 50/year solution means closing around 80 hospital units, and replacing them with about 35. The 100/year solution would close 94 units of the 99, and replace them with about 30. Moving personnel around en masse is likely to lead to a period of poor performance, among other difficulties. It is noteworthy that Holt doesn’t advocate closing units, but simply says that “Variations in death rates do not equate to deficiencies in the quality of care received, but what is clear is that these results require further investigation, which must begin with confirming the accuracy of the data before hospitals are labelled as dangerous.”
Consider the reduction to a minimum of 50 elective AAA operations/year. The hospitals that would be closed or combined also perform nearly 700 emergency AAA operations a year, or about 60% of the total. Their mortality rate (35%) is barely different from the national average (33%), and the 714 deaths are far more than the 262 resulting from planned operations. It’s hard to know what this means, but it does suggest that a widespread change to hospital structures that might, statistically, save 9, or 26, or perhaps around 50 lives in elective surgeries (out of nearly 10,000 procedures), needs to be weighed first in terms of potential effects on the emergency surgeries. For instance, if hospitals were to be closed, it seems indubitable that some patients would be needing longer to reach hospital. And in an emergency, time is crucial.
I’m not an expert on this. The essential issues around elective and emergency procedures may be different than I think, or maybe there’s no link. But it is a general principle that an effect that is barely statistically discernible from noise is likely to be an artifact of much bigger effects, unless the study and the analysis have been exactingly designed to control for all important confounders – which, in this case, given the nature of the data, we can’t really do.
“Demonstrating safety”
Holt also argues that “a minimum of 50 elective cases should be performed each year by each hospital in order to demonstrate safety.” Now, it is true, as we have discussed, small numbers of operations make it difficult to measure the mortality rate accurately, and so problems may go unrecognised longer. But while this argument might appeal to a managerialist, for whom measurement and evaluation are more important than actual safety, it doesn’t make very much sense. It’s true that a hospital that does 10 operations a year will take five times as long to provide a given level of precision in evaluating its performance as a hospital that does 50 a year. But so what? The number of patients at risk in the two hospitals of the time required for evaluation is exactly the same. And the smaller hospital will probably have killed fewer patients before it gets noticed, if its performance is disastrously bad.
Back to the Health Secretary
So, ultimately, I’d just say that I think the Guardian’s journalists could have been less sensational, and less accusatory. Some of their “experts” could have done the same. The makers of policy, in particular the health secretary, need to weigh many different considerations, only some of which are directly technical medical issues. They’re usually not trying to kill people, they’re usually not even indifferent to human suffering. They may be competent or incompetent, wise or misguided, but judging them from a narrow medical perspective is rarely adequate. And it’s particularly offensive when journalists are accusing a politician of destructive narrow-mindedness, not out of conviction, but just because it’s a convenient mallet with which to whack the clay foot of a powerful idol.
